GuitarML FAQ
This article answers some commonly asked questions about the modelling methods in GuitarML’s projects and demonstrates the results of several amp/pedal captures. The limitations of these techniques are also explained.
To return to the main GuitarML website, click here
What is GuitarML?
GuitarML uses machine learning to model real amps and pedals. The GuitarML portfolio encompasses several guitar plugins that let you create and play amp/pedal captures in real time on your electric guitar.
GuitarML software is free, mostly open source, and receives funding through donations from Patreon/Github Sponsors. The modelling techniques used in the plugins are based on research papers from the Aalto University Acoustics Lab in Finland (no affiliation). These papers describe how to use neural networks for black box modelling of guitar effects and amplifiers.
How does the modelling process work?
- “Before” and “after” audio recordings are made using the target amplifier or pedal. There are several ways to accomplish this. You can use a signal/buffered splitter to record two tracks simultaneously:

Or, you can take a pre-recorded input track and play it through the target device to get your “after” recording. The Proteus and SmartPedal plugins have a Capture Utility colab script and audio input files for accomplishing this. Recommended to use a reamp device prior to the target amp/pedal when using this method.
2. The “before” and “after” recordings are used by the software to capture a digital model. The neural network is made up of layers of parameters which are gradually adjusted to mimic the dynamic response of your amp/pedal. The training code found on Github can be used directly, but the easiest method is to use the Google Colab scripts in the Proteus or SmartPedal Capture Utility zip files.
3. The resulting model (.json file) can be loaded into the appropriate plugin and played in real-time using an electric guitar and audio interface, or through the NeuralPi hardware.
How good do the captures sound compared to the real amp/pedal?
To explain this, I’ll use a couple of real world examples of pedal and amp captures. The target sound and the modelled sound will be compared using audio and plots of the signals. In each graph below, the purple line is the input guitar signal, the red is the target amp/pedal signal, and the green is the predicted signal from the trained model. Each graph shows approximately 8 milliseconds of audio.
Note: All of the below examples use the Automated-GuitarAmpModelling code, with the stateful LSTM implemented in NeuralPi, Chameleon, and TS-M1N3. For SmartAmp/SmartAmpPro examples, see the “Tech Articles” referenced in the Product Downloads section of the GuitarML website.
Little Big Muff (Distortion/Fuzz/Sustain Pedal)


Audio from actual pedal:
Predicted audio from GuitarML capture:
Dumble ODS Clone direct output through load box (High Gain settings)

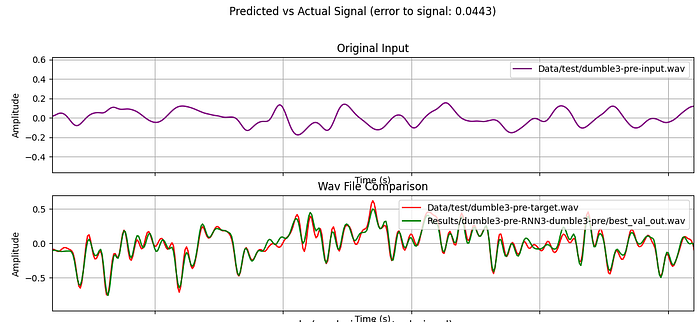
Audio from actual amp:
Predicted audio from GuitarML capture:
Xotic SP (Compressor Pedal)

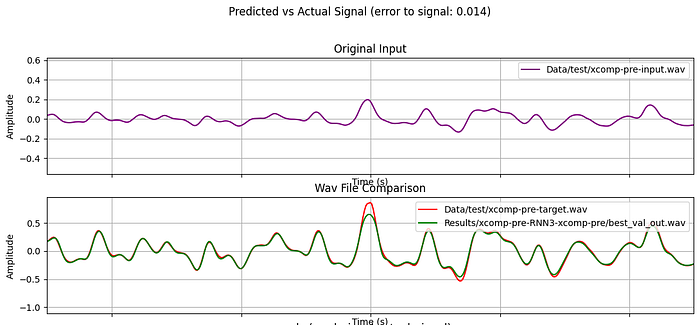
Audio from actual pedal:
Predicted audio from GuitarML capture:
Accuracy is determined by the “error-to-signal ratio”, which is a modified version of MSE (mean squared error). Any loss below 0.05 can be considered a successful capture, but your ear should be the final judge of quality.
What are some limitations?
- You can only capture “signal” based effects, as opposed to “time” based effects. Distortion, overdrive, and some compression can be captured because they have a more immediate effect on the guitar signal. Reverb, delay, chorus, flange can’t be captured because the signal is modulated over a longer period of time. These effects should be added separately to your signal chain.
- The capture can only be as good as the recorded audio samples. This is typically not an issue for pedals or devices that you can record with a direct output. However, any noise introduced in the recorded signal will also be captured. You can use a microphone when recording amp samples, which adds it’s own color to the sound. It also introduces speaker/cabinet dynamics, which may or may not be properly captured by the machine learning. The recommended recording method for amps is to use a load box to capture the direct output, or a line out if available. The resulting model can then be used with Impulse Responses to swap out different cab/mic combinations.
Note: You can modify the recorded sample prior to training to attempt to remove noise, change EQ, or add digital distortion/modulation.
Why aren’t all models compatible with every plugin?
The GuitarML plugins were originally experiments into using machine learning for modelling amps/pedals. Several different neural net models were tested in order to find the best one. Even though every model uses the JSON format, the structure of the data is different for each model, and therefore not compatible with models of different types.
Here is a list of the current plugins and their neural net model types:
- Proteus, EpochAmp, NeuralPi, Chameleon, TS-M1N3: stateful LSTM
- SmartAmp and SmartPedal: WaveNet
- SmartAmpPro (Not officially released and no longer in development, but available on Github): Combination of 1-D Convolution and stateless LSTM
I conducted a trade study while developing the NeuralPi that is helpful for explaining the different strengths and weaknesses of each model:

The stateful LSTM and WaveNet have the highest accuracy, but LSTM wins in real-time performance. CPU usage with the stateful LSTM is comparable to other commercial plugins using traditional modelling methods. Training time of stateful LSTM falls between WaveNet and stateless LSTM. The sizes of the neural networks also play a major factor in CPU usage and accuracy, so it is difficult to make a direct comparison.
The other two models have their own merits. The training used in SmartAmpPro is extremely fast, and can be completed on a CPU (instead of GPU) in under 5 minutes. It can model clean sounds and mild distortion pedals accurately, but has difficulty with amplifiers and higher distortion. The sound can also have a harsh quality not present in the target recording.
WaveNet requires more computation, and has roughly 4 times more CPU usage compared to other guitar plugins. It’s sound quality is very good and can surpass LSTM (based on Aalto research paper data).
The training code throws an error when trying to read my sample input/output wav files.
The wav files have to be in a specific format before using it with any of the training codebases. These are the requirements:
- Must be 44.1kHz samplerate.
- Must be Mono (as opposed to stereo).
- Can’t have extra metadata, such as tempo information, which is sometimes added automatically by your DAW.
- The new Colab Script code used with Proteus and SmartPedal can accept PCM16 or FP32, but the old code only accepts FP32.
Note: Most DAW’s have an export feature that allow you to format the exported wav file from your tracks to meet the above requirements.
What is Google Colab and how can I use it to create GuitarML models?
Google Colab is a free python environment in the cloud, where you can run code through a web browser. This environment includes both Tensorflow and Pytorch (the frameworks used to do the machine learning part). This eliminates the need for downloading and installing all the dependencies on your local computer. It requires a Google account to use. After recording your input/output sample wav files, follow these steps:
- Download the appropriate Capture Utility zip file (Proteus or SmartPedal) from GuitarML.com. This contains an input wav file and a colab script specific for either the Proteus or SmartPedal plugins.
- Go to the Colab Website.
- Click “File” and “Upload Notebook”, and upload the Colab script downloaded from GitHub.
- Switch to the GPU runtime to train using GPUs (much faster than CPU runtime). This is done from the “Runtime” dropdown menu at the top of the webpage.
- Upload your two sample input/output wav files. You may need to run the “!git clone …” section of code first, in order to create the project directory. The wav files can then be uploaded to the project folder in the left hand menu. When using the Capture Utility colab scripts, follow the instructions at the top of the script after loading into the Colab website.
- Run each block of code by clicking the small “play” icons for each section in the main view. Follow any commented instructions (green font) before running each block of code.
- When you run the actual training, you should see an output of it’s progress.
- When training is complete, you can run the last block of code to create plots for comparing the target signal and the newly created model.
See the GuitarML Youtube tutorials for a step by step guide for training models for Proteus and SmartPedal.
Plugin Specific Questions
Why does SmartAmp/SmartPedal sound glitchy or crackly?
The underlying WaveNet model used in SmartAmp uses a high amount of CPU for DSP processing. If the buffer cannot be processed in time, there are gaps in the output audio, which sounds really bad. There are no plans to attempt to further optimize WaveNet, as the LSTM model provides at least a 4x speed improvement with improved sound and training time. There are no current plans to update SmartAmp to the LSTM model, as using WaveNet is still a novel approach to black box modelling and may be of interest to some people.
A couple of things that help SmartAmp performance:
- Train models with less parameters (less layers/channels). This will reduce the accuracy, but will run faster in real-time.
- Plug in your laptop and set the system performance to the highest setting.
- Set your DAW thread priority to the highest setting.
- Increase your buffersize in your audio device settings.
Click below to return to the GuitarML website:
Thank you for reading! For questions not covered here, please email to:
smartguitarml@gmail.com